Hello, hope you have your Yorkshire tea to hand and sitting comfortably ready to read today’s blog. In it I am going to be doing some machine learning with tidymodels to predict the outcome of some twenty20 cricket matches.
I am using the data from cricsheet as used in this blog and using the win probability added metric to create variables for prediction
Twenty20 Win Probability Added
I might write an extra blog on reading the data and creating the data frame of all the JSON data but that’s beyond the scope of today. I have 4 data frames:
- ball by ball data of a lot of t20 matches totaling over a million balls
- the information for that match – teams playing, location, date, and competition
- the players playing in the match
- Win probability added for batting and bowling for each bowler and competition they have played in.
These 4 data frames will be used in various points to create the data required to test and develop the model. The first part of this process is to calculate the result of the match. In cricket, if you were batting first and won you win by the number of runs you score more than the opposition. Whereas if the team batting second wins they win by the number of wickets they had lost less than 10. This means the model would have an inconsistent prediction variable which is not going to work for machine learning. Therefore I need an outcome variable that is not susceptible to this problem. To do that I will be taking each team run rate for their innings calculaating how many runs that equate to over the full 120 balls and then calculating the difference between the two teams
# using the dat2 dataframe which has the ball by ball data
teamscore <- dat2 %>%
#identifying when a ball took a wicket
mutate(wickloss = if_else(filt == "stumped", 1,
if_else(filt == "run out", 1,
if_else(filt == "retired out", 1,
if_else(filt == "retired hurt", 1,
if_else(filt == "obstructing the field", 1,
if_else(filt == "lbw", 1,
if_else(filt == "hit wicket", 1,
if_else(filt == "caught and bowled",1,
if_else(filt == "caught", 1,
if_else(filt == "bowled", 1, 0))))))))))) %>%
%>%
# calculating the total wickets in an innings
group_by(team, file) %>%
summarise(total_run = sum(totrun), n = n(), total_wicks = sum(wickloss, na.rm = T)) %>% # calculating the total innings runs by team and match
left_join(match_etras, by = c("team", "file")) %>% # joing the innings extras
mutate(exta = if_else(is.na(n.y), 0, as.double(n.y))) %>%
mutate(balls_f = n.x - exta) %>% # calculating the legitimate balls faced
mutate(rr = if_else(total_wicks == 10, total_run/120, total_run/balls_f)) %>% # calculating the runs per ball
ungroup() %>%
group_by(file) %>%
mutate(teamno = 1:n())
# filtering for all team 1 s
teamscore1 <- teamscore %>% filter(teamno ==1 )
# filtering for team 2s
teamscore2 <- teamscore %>% filter(teamno ==2 )
# filtering for team1s a then renaming the rr to the oposition
teamscorea <- teamscore %>% filter(teamno ==1 ) %>%
select(file, rr)
colnames(teamscorea)[2] <- "rr_op"
teamscoreb <- teamscore %>% filter(teamno ==2 ) %>%
select(file, rr)
colnames(teamscoreb)[2] <- "rr_op"
# joining the team 1s to the team 2 as oppositions
teamscore12 <- teamscore1 %>% left_join(teamscoreb, by = "file")
#joining the team ones to the team 2 as opossitions
teamscore22 <- teamscore2 %>% left_join(teamscorea, by = "file")
calculating the score differences
team_scor_ov <- teamscore12 %>% bind_rows(teamscore22)

Running the above code produces a data frame as above. Now that the calculation is complete I can calculate the run difference for both teams.
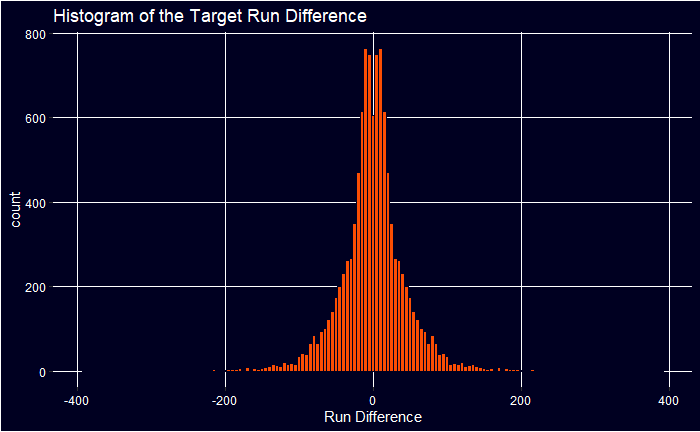
Above you can see the distribution of the target is normally distributed with a lot of matches reasonably close. That will make it hard to be accurate as clear victories are probably easier to predict. Now I have the match performances I need to have measures for the quality of the players in either team. The two predictors I will be using to start with are the difference in win probability for the top 6 batsmen on a team and the top 5 bowlers. The top six batsmen as they’re the ones most likely to bat and there be the most accurate batting data and the minimum number of bowlers you will use is 5.
#mach_play is the list of players in the match
# info 2 is the information of the match toss, location ect
# play stats is a data frame with all the statistics of a player for all the competitions they have been in
match_play2 <- match_play %>% left_join(info2, by = "file") %>%
mutate(comp2 = if_else(comp_t == "International", "international", comp)) %>%
left_join(play_stats, by = c("player", "comp2")) %>%
group_by(team, file) %>%
mutate(bowlrank = rank(desc(bb))) %>%
filter(bowlrank < 6) %>%
ungroup() %>%
group_by(team, file) %>%
summarise(bowl_q = mean(wpa6)*100) %>%
ungroup() %>%
group_by(file) %>%
mutate(team2 = 1:n())
match_play4 <- match_play %>% left_join(info2, by = "file") %>%
mutate(comp2 = if_else(comp_t == "International", "international", comp)) %>%
left_join(play_stats, by = c("player", "comp2")) %>%
group_by(team, file) %>%
mutate(bowlrank = rank(desc(bb))) %>%
filter(bowlrank < 6) %>%
ungroup() %>%
group_by(team, file) %>%
summarise(bowl_q = mean(wpa6)*100) %>%
ungroup() %>%
group_by(file) %>%
mutate(team2 = n():1)
colnames(match_play4)[1] <- "Opp_t"
colnames(match_play4)[3] <- "opp_b"
match_play5 <- match_play2 %>%
left_join(match_play4, by = c("file", "team2")) %>%
mutate(bowldelt = if_else(bowl_q > 0 ,bowl_q - opp_b,bowl_q - opp_b ))
Above is how the bowl difference is calculated between both teams. For the batsmen, it was the same code. That was joined to the score for the matches to create this data frame :
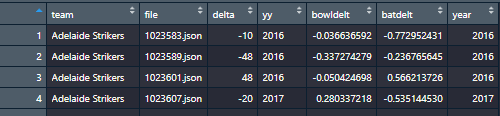
It has the delta in the result and then the difference in batting and bowling quality. Now is the time to create a model. I’m going to start by creating a random forest on the two variables.
#creating the testing and training data sets
split <- initial_split(model_dat, prop = 0.75)
train_dat <- training(split)
testing_dat <- testing(split)
Above I create the testing and training set of the data. I also decided to look at matches before 2022 so I can compare the model to actual results
crick_rec <- recipe(delta ~ bowldelt+ batdelt, data = train_dat)
tune_spec <- rand_forest(
mtry = tune(),
trees = tune(),
min_n = tune()) %>%
set_mode("regression") %>%
set_engine("ranger")
tune_wf <- workflow() %>%
add_recipe(crick_rec) %>%
add_model(tune_spec)
set.seed(455545)
cick_folds <- vfold_cv(train_dat)
doParallel::registerDoParallel()
set.seed(44355)
tune_res <- tune_grid(
tune_wf,
resamples = cick_folds,
grid = 20
)
tune_res
tune_res %>%
collect_metrics() %>%
filter(.metric == "rmse") %>%
select(mean, min_n, mtry, trees) %>%
pivot_longer(min_n:trees,
values_to = "value",
names_to = "parameter"
) %>%
ggplot(aes(value, mean, color = parameter)) +
geom_point(show.legend = FALSE) +
facet_wrap(~parameter, scales = "free_x") +
labs(x = NULL, y = "RMSE")
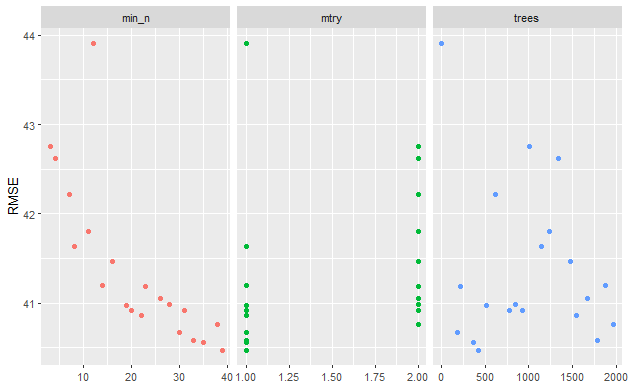
Summary of the model results shows that mtry doesn’t really make much difference. That’s expected as there’s only 2 variables. Trees also seems like it doesn’t really change the results. Min_n tuning parameter does make a difference though with a value around 40 being the best for this model.
select_best(tune_res)
final_rf1 <- finalize_model(tune_spec, best)
final_rf1
fin_rf2 <- final_rf1 %>%
fit(delta ~bowldelt+ batdelt , data = testing_dat)
preds <- predict(fin_rf2, new_data = testing_dat)
testing_pred2 <- testing_dat %>% bind_cols(preds) %>%
ungroup()

I then take the best-fitted model and I tested it on the testing data from the earlier split. The model has an RMSE of 32 which is lower than the value when tuning the model suggesting this is a good fit as it has generalized better to new data. Finally, lets look at how it would have predicted the recent West Indies and England Series
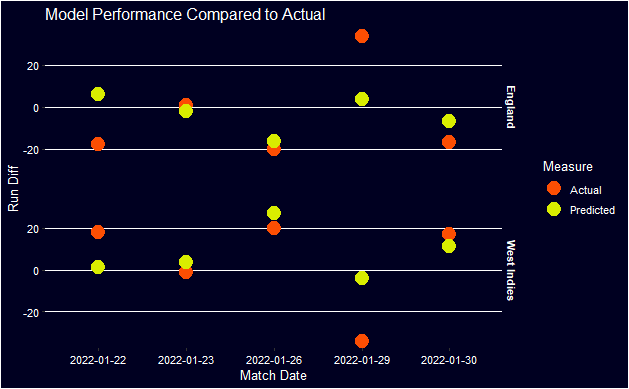
Overall the model predictions follow the basic trend of the actual performance. There are a couple of matches it is called wrongly but that’s to be expected. The worst predicted match is the first one as it was a predicted win for England but it was a clear win for West Indies. I’m going to further develop this by looking at other types of models that can be done and comparing the performance of a classification model.

please consider if_else(x %in% c(‘a’, ‘b’, ‘c’), 1, 0), or case_when(x == ‘a’ ~ 1, x == ‘b’ ~ 1, TRUE ~ 0) instead of those horrendous nested if_else’s.
also your readers and future colleagues would thank you if you fix your horrendous style https://style.tidyverse.org/ https://google.github.io/styleguide/Rguide.html
i normally wouldn’t bother but this is so bad that my ocd kicked in.
LikeLike
[…] article was first published on Sport Data Science, and kindly contributed to R-bloggers]. (Anda dapat melaporkan masalah tentang konten di halaman […]
LikeLike
[…] article was first published on Sport Data Science, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here) […]
LikeLike